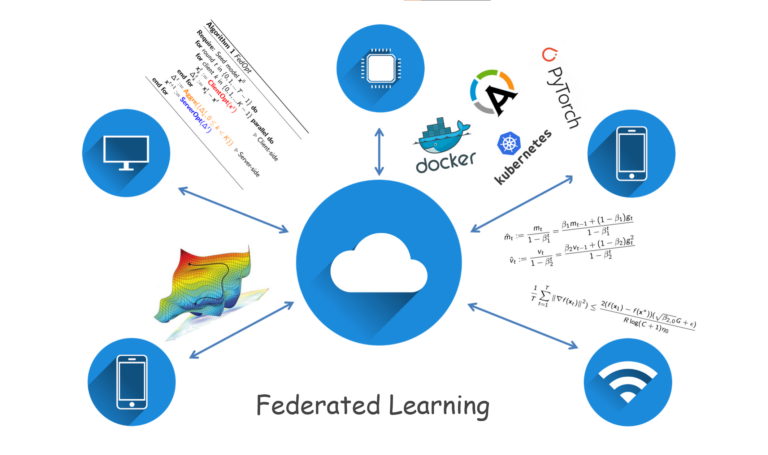
Federated Learning: Distributed Optimization and Applications
Federated machine learning (FedML) involves the development of algorithms and applications that enable distributed machine learning across multiple devices or data sources while maintaining data privacy and security. We study FedML broadly in the group. Some specific recent topics include distributed optimization and developing novel approaches for federated learning that can address challenges such as communication and computation efficiency, data heterogeneity, and model drift. Ultimately, our research aims to advance the state-of-the-art in federated optimization and enable its practical deployment in real-world applications.
People: Li Ju, Salman Toor, Andreas Hellander
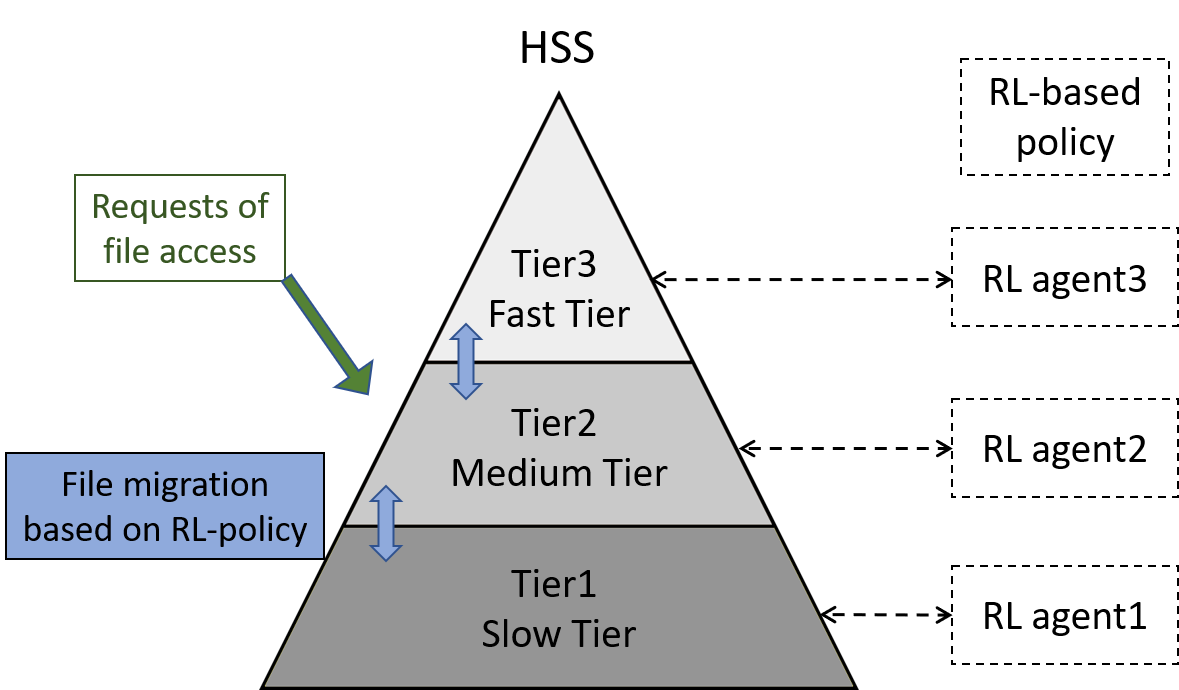
Hierachical Storage Management
In our recent research project ‘Efficient Hierarchical Storage Management with Reinforcement Learning’, we focus on designing cutting-edge solution for managing large datasets in Hierarchical (Multi-tier) Storage System (HSS). Our recent paper [linked to the text] presented an efficient hierarchical storage management framework using a well-designed autonomous data placement policy empowered by Reinforcement Learning (RL). In the framework we define an environment where its state variables represent the status and properties of each storage tier in HSS, and applied RL to define the data placement policy by finding the best data movement actions.
People: Tianru Zhang, Salman Toor
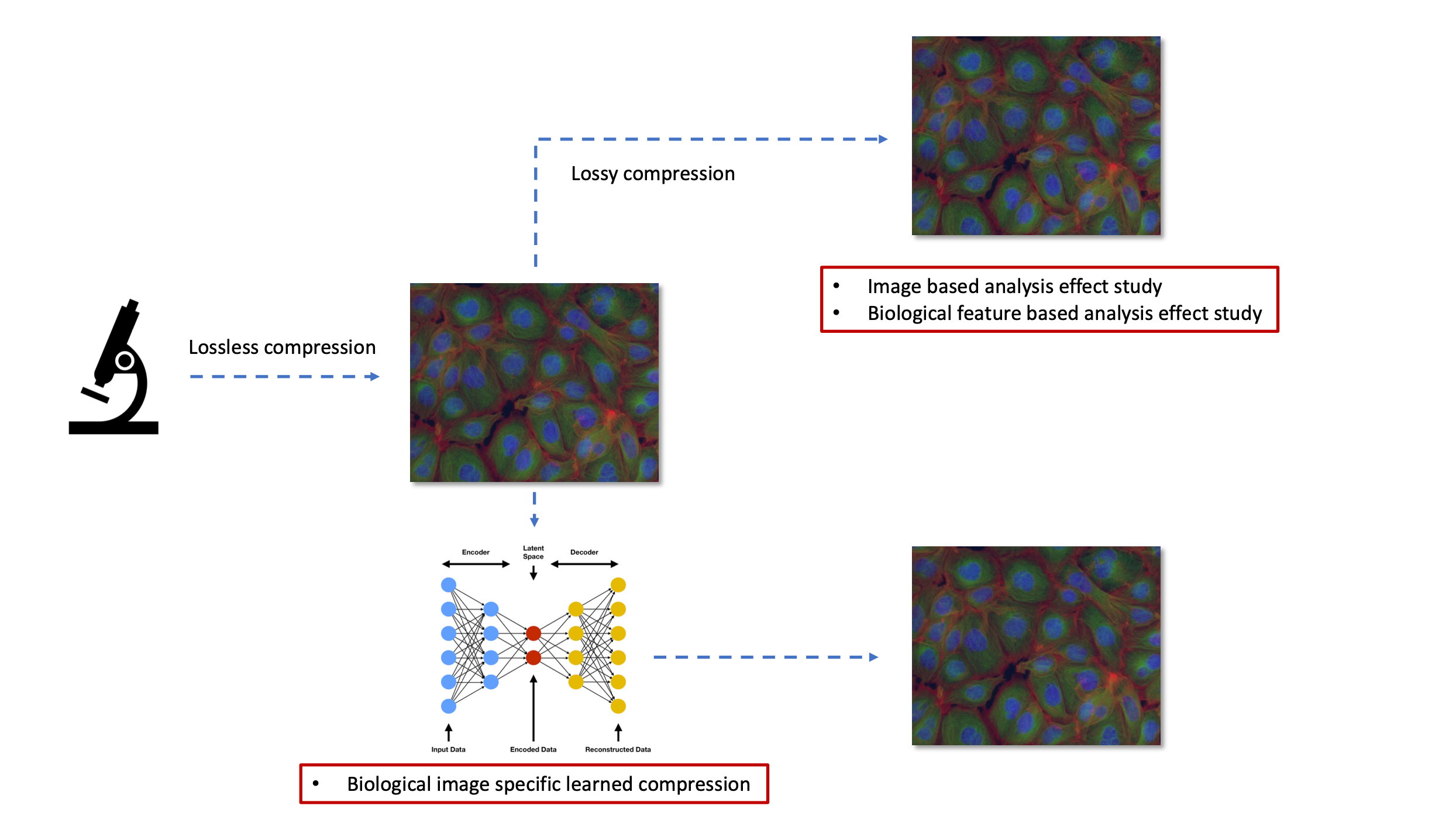
Lossy Compression on Biological Image Analysis
With the development of modern microscopes and experiment automation, a massive amount of microscopy images are generated, which can be gigabytes or even terabytes of data in a single experiment. To deal with the explosion of microscopy image data, lossy compression could be a potential way, however, its effects on analysis are unclear. This project, as a part of the HASTE project, mainly focuses on studying the effects of lossy compression on biological image analysis, and aims to propose a learned compression technique that specifically devised for biological images. Different of existing lossy image compression methods designed for human vision, this technique will maintain the information of more interest for downstream biological analysis while compressing.
People: Xiaobo Zhao, Andreas Hellander
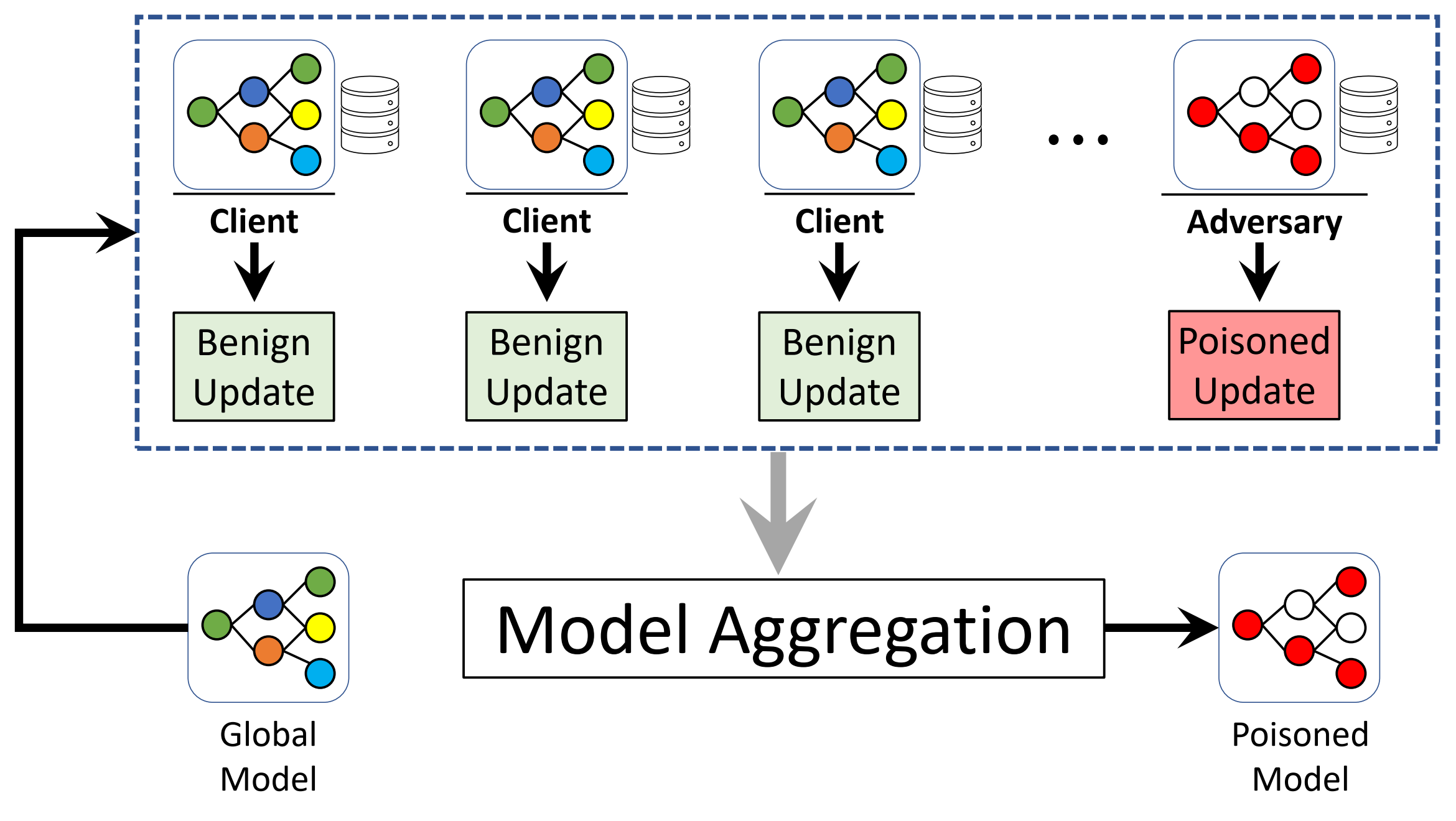
Secure and Privacy-Preserving Federated Machine Learning
Federated machine learning (FedML) is a promising approach that enables multiple participants to collaboratively train a shared machine learning model while allowing them to keep their data private. However, due to its decentralized nature, FedML is vulnerable to various security and privacy threats. Under this project, we study various security / privacy challenges and their impact in production grade federated machine learning systems in depth. Our research aim is to design practical solutions that can be used in production to help counter these threats.
People: Usama Zafar, Salman Toor
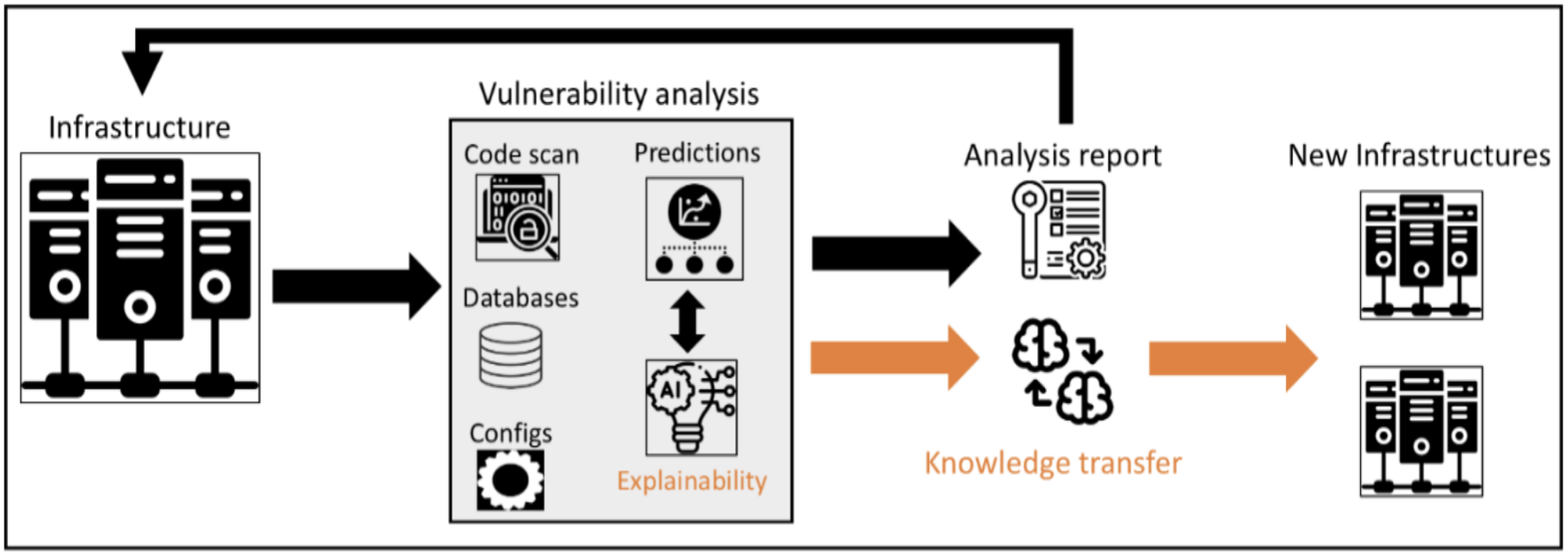
Data-driven Vulnerability Analysis for Critical Infrastructures
Software applications and reliable communication are key to offer regular
and mission critical services online. Mission critical services are part of critical
infrastructure sectors like healthcare, finance, communications, and power
generation and distribution. To support a reliable, secure, and efficient
offering of software services for critical infrastructures, the cybersecurity and
trustworthiness of software and computing infrastructures are vital. It is of
utmost importance to take all possible measures to secure the computing
systems supporting critical infrastructures and ensure uninterrupted
availability of services. To secure these systems, our project proposes to
design and develop a comprehensive and proactive vulnerability analysis
framework for software applications running on critical infrastructures. The
proposed project, with its well-defined focus areas, is a cross-disciplinary
effort within data science, machine learning, and cybersecurity with the
purposes.
People: Zhenlu Sun, Salman Toor
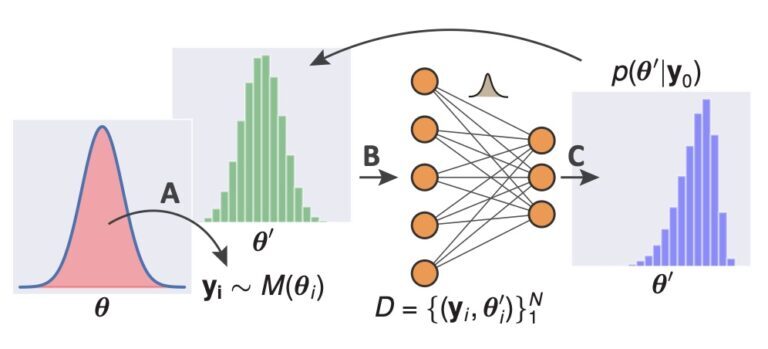
Scalable Likelihood-Free Parameter Inference of Stochastic Simulation Models
Our research group is dedicated to addressing the complex challenges of parameter inference in stochastic simulation models, especially when we have limited observed data in the form of time series. We specialise in situations where traditional likelihood functions are either unavailable or computationally infeasible. These processes can be computationally demanding, particularly for large-scale problems with a high number of parameters to infer. To overcome these challenges, we integrate machine learning techniques such as neural networks for generating summary statistics and neural density estimators as surrogate models. Our ultimate goal is to develop scalable, efficient, and accurate methods for parameter inference, focusing on questions like efficient parameter selection, accurate comparison of high-dimensional time series, and efficient posterior distribution estimation.
People: Mayank Nautiyal, Prashant Singh
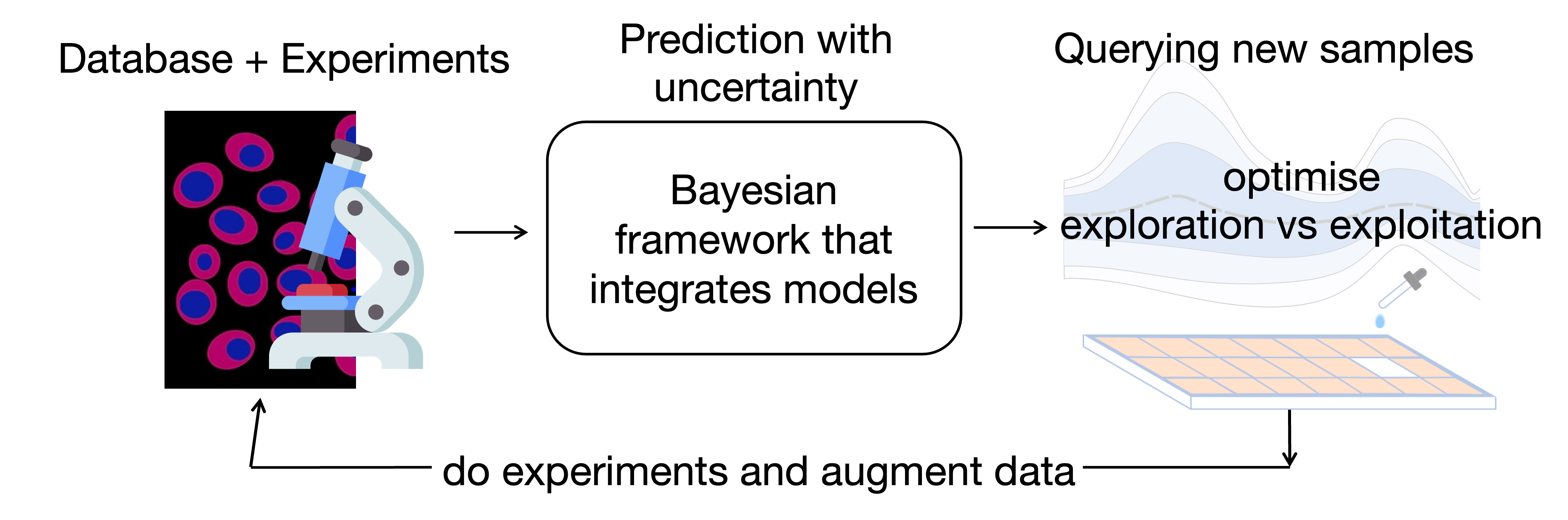
Statistical Sampling for Large-Scale Scientific Experiments
In this research project we address the challenges of scale and complexity while conducting large-scale scientific experiments, with particular focus on phenotypic drug and drug combination screening experiments in close collaboration with the Pharmaceutical Bioinformatics research group at Uppsala University.
To successfully fight a disease and have less severe side effects, people are trying to find existing drug compounds that work together in synergy. But this leads to combinatorial explosion if one decides to study the efficacy of all possible drug combinations from a given set of compounds. The setting fits nicely into the framework of Bayesian optimization which focuses on the balance between exploration and exploitation. Hence, we are designing a decision-making algorithm that will assist the experiments on drug combination in a robotic laboratory. This method will employ Bayesian approach to 1. combine statistical learning with assumptions from different biological models, 2. make predictions with uncertainty estimates important for the exploration-exploitation tradeoff, and 3. will be scalable to be applied to large datasets.
People: Aleksandr Karakulev, Prashant Singh